DevOps é cultura ou ferramentas?
Apr 30, 2020 · 21 minute read · Commentsportuguesdevopsagilesretoyota production system

DevOps é um termo independente da definição, soa muito bem aos ouvidos das pessoas que trabalham com Tecnologia da Informação. Ele é a junção do termo Software Development + Operations. Numa tradução livre, significa juntar áreas de Desenvolvimento de Software e Operações de TI, ou como chamamos no Brasil de Infraestrutura. Sem dúvida, você já deve ter ouvido algumas frase como essas:
Sou Engenheiro DevOps!
Aplicamos DevOps aqui!
O DevOps diz tal coisa…
Contratei uma consultoria DevOps para implementar ferramenta ABCDEF.
DevOps é cultura e não ferramenta!
DevOps é desenvolver aplicações Cloud Native!
Provavelmente, já ouviu deve ter escutado outras frases ou variações das acimas mencionadas. Não é possível afirmar de forma contundente que estas frases estão erradas porque DevOps é um termo fluído, complexo e nem tão simples de definir.
Em algumas conversas em eventos havia frustração sobre o que é DevOps e como ele aplicado nas organizações que eles trabalhavam. Ao tentar entender qual era a definição deles e de onde eles trabalhavam, havia algo em comum em todas as conversas. O entendimento sobre DevOps ou mesmo Agile era bem diferente de quem estava implementando e quem estava patrocinando.
Não pode-se afirmar que há culpados, o entendimento é diferente para papéis diferentes numa organização, ou mesmo dentro de uma mesma equipe. Há razão para é falta de um definição clara do que é, de como se aplica, ou uma referência clara como Manifesto Ágil para “Agile”, ou como alguns preferem Agilidade.
Mesmo o Manifesto Ágil, há um profusão de variações para colar no buzzword da “Agilidade”. Então, o que é chamado de DevOps será muito diferente entre as pessoas ou mesma pessoa mas em épocas diferentes. Um bom exemplo sou eu, basta ler alguns textos mais antigos aqui neste espaço ou rever algumas das minhas apresentações, tentei em várias tentativas diferentes definir o que é DevOps.
DevOps torna-se um dos meus buzzword favoritos porque não há uma delimitação clara do que é, quais papéis estão envolvidos, técnicas ou ferramentas. Um outro bom exemplo é ler a ementa de qualquer curso ou treinamento relacionado a ele, todos serão diferentes pela a razão já mencionada: DevOps é definido dentro do contexto de cada pessoa e organização.
Ainda sim, é possível tentar identificar alguns padrões de técnicas, métodos, ferramentas e conceitos aplicados nas organizações que dizem que usam ou implementam.
Nos últimos anos cresceu muito o uso do termo “Cultura DevOps” como uma contraposição, não necessariamente oposta, as implementações DevOps baseadas somente em ferramentas. Não tenho dados ou uma fonte de estudo a respeito e seria presunção minha afirmar que Cultura e Ferramentas são maiores vertentes. Contudo, empiricamente posso dizer que são as duas vertentes que há debates mais calorosos nas empresas.
O que é Cultura DevOps?
O senso comum é as equipes de desenvolvimento de software e infraestrutura trabalhando juntas em pró de um mesmo objetivo.

A realidade é quase sempre mais complexa do que vende-se a Cultura DevOps como a imagem acima. Quase sempre, a uma implementação DevOps ocorre ao mesmo tempo de outras “Culturas” ou métodos como Scrum, OKR, Startup Enxuta, Management 3.0, etc. Todas lutando para ter seu lugar ao sol.
Por que onde trabalho comprou a ferramenta XYZ como DevOps?
Ferramentas são tangíveis, ainda que isso soa um pouco estranho se considerarmos software como ferramenta é algo tangível. Neste contexto, de entrega ou implantação numa empresa são mais fáceis de identificar através de diversas evidências: manuais de instalação ou operação, registro de eventos da ferramenta implementada, etc.

Apesar de serem tangíveis, há quase sempre um sentimento de frustração na maioria dos casos de implementação das ferramentas relacionadas a DevOps. Isso porque as expectativas estavam muito altas como se elas fossem bala de prata. Ou seja, automaticamente os problemas de comunicação, processo e cultura da empresa fossem resolvidos. Como se comprar um carro novo resolvesse o problema da rua esburacada que ele tem que passar todos os dias.
Cultura não é tão simples de definir ou implementar
Na preparação da minha apresentação sobre “DevOps, cultura e ferramentas” procurei a definição de Cultura. Para minha surpresa, a definição dela é variada em diversas áreas do conhecimento. Um exemplo o quanto diverso é, Kroeber e Kluckhohn identificaram no livro (1952) “Culture; a critical review of concepts and definitions” compilaram 164 definições e conceitos diferentes para Cultura.
Se é difícil para acadêmicos ter uma definição consensual do que é Cultura, implementar na prática uma nova Cultura pode ser ainda mais complexo e difícil. Um exemplo prático é a implementação do Sistema Toyota de Produção (Toyota Production System) na General Motors (GM). A ocidentalização do TPS tornou-se mais conhecida com o nome de Lean.
Em 1984 a GM e Toyota criaram uma Joint Venture chamada NUMMI na fábrica da GM em Freemont. Esta fábrica tinha um histórico de baixa produtividade e problemas disciplinares, a GM considerava fechar esta planta fabril antes da criação da Nummi. A implantação do TPS a fez se tornar uma das mais produtivas dos EUA em pouco tempo e com praticamente as mesmas pessoas de antes de 1984.
O sucesso da implementação do TPS em Freemont foi tão significativo ao ponto da GM decidir implementar para todas fábricas dela. Entretanto, o mesmo sucesso não foi reproduzido totalmente, algumas fábricas conseguiram implementar mas muitas outras, não. A razão, segundo o livro “How to Machine Change the World” de James P. Womack, Daniel T. Jones e Daniel Roos é “O problema fundamental foi fazer a transição da produção em massa para Produção Enxuta (Lean) mudando o trabalho de cada funcionário e gerente.”
A dificuldade não foi somente mudar a forma de como as fábricas produziam carros, também significava mudar como as pessoas trabalhavam em diferentes níveis hierárquicos, a cadeia produtiva, etc. Afinal, a GM aperfeiçoou a produção em massa criada criada por Henry Ford ao longo de décadas do século passado.
Um outro caso de uma instituição financeira brasileira implementou Agilidade de maneira um pouco abrupta, a mudança foi de cima para baixo. Uma decisão da alta gerência mudar de forma muita rápida, em poucas semanas foi determinado mudar todo o processo de produtivo da área de tecnologia. Desenvolvedores, Qualidade, Operações de TI, demais perfis e áreas tiveram que usar o modo “Ágil” para que as novas funcionalidades, correções de bugs, etc fossem lançada em produção. Após a data da virada para o modo Ágil, foram semanas de muitas equipes batendo cabeça até conseguirem voltar manter o fluxo produtivo aos níveis de antes da mudança e posteriormente atingirem melhoria da produtividade.
O que é Cultura?
Até aqui tentei mostrar como Cultura é um termo fluido como água, também tentei mostrar como implementar uma nova Cultura em uma organização como GM é desafio complexo e de longo tempo. Contudo, para tentar responder o que é Cultura DevOps precisa partir de algum lugar. O ponto de partida é a definição do antropólogo Franz Boas usou no livro The Mind of Primitive Man de 1911:
“O sistema de compartilhamento de crenças, valores, costumes, comportamentos e artefatos que os membros da sociedade usam para lidar com seu mundo e uns com os outros. São transmitidos de geração em geração através da aprendizagem”
A definição dele se encaixa numa empresa, órgão público, organizações não-governamentais, etc. exceto pela última parte do texto. Não há, na maioria, gerações de pessoas num cenário como esse, a rotatividade é bem maior, poucos anos, meses e/ou algumas semanas. Este contexto no mundo corporativo é conhecido como Cultura Organizacional, o Business Dictionary define como “*… valores e comportamentos que contribuem para um ambiente psicológico e social de uma organização*”.
A Cultura de uma organização muda um pouco a cada mudança de pessoas que trabalham nela, a cada nova pessoa entra ou sai uma parte dos valores e comportamento é alterada com maior ou menor influência. Isso torna a cultura organizacional única e irreproduzível na totalidade, pode parecer um contra-senso porque muitas pessoas e empresas atualmente tentam reproduzir o modelo Spotify de organização de equipes. Ao analisar como este modelo foi copiado e implementado irá identificar que nenhuma o reproduziu o modelo na totalidade, para ele ser implementado foi necessário adaptar o modelo original para que funcionasse. Portanto, não se copia por completo a cultura de uma organização para outra.
E a Cultura DevOps? Não importa a definição que você use para a Cultura DevOps, a implementação será única e diferenciado de qualquer outra. As ferramentas e processos que funcionam numa empresa não, necessariamente, irão funcionar numa instituição pública ou mesmo numa empresa similar.
Talvez esteja mais confuso agora do que antes de iniciar a leitura deste texto. Deve estar perguntando…
É possível implementar DevOps com Kubernetes? E sem Kubernetes?
É posível implementar DevOps em Mainframes?
É possível implementar DevOps sem um pipeline com Jenkins, Gitlab CI ou Circle CI?
É possível implementar DevOps sem Observabilidade (Observability)?
É possível implementar DevOps sem usar os provedores de nuvem (IaaS), tudo em datacenters?
É possível implementar DevOps…
A resposta para todos as perguntas é SIM. DevOps é um meio e não um fim, portanto, é um meio de melhorar os processos produtivos relacionados a Tecnologia da Informação. Há ferramentas, processos, métodos e técnicas que podem tornar a melhoria mais rápida e menos traumática, o fundamental é evolução do gradual de produtos, serviços, sistemas e pessoas.
Qual a maneira efetiva para implementar DevOps?
Há diversas maneiras de implementar e muitas delas podem ser muito efetivas para determinadas situações e contextos. Algumas práticas e tecnologias são reconhecidas como mais eficientes, exemplos: Containers, Continuous Delivery, Equipes auto-suficientes (conhecidas atualmente como Squads), Observabilidade, etc. Não há fórmula mágica para mudanças culturais, ao tentar aplicar a “mesma receita” para implementar uma nova cultura para diferentes organizações é tratá-las de maneira dogmática.
Algumas situações não é possível implementar o uso de containers logo de início, outras o ganho de produtividade é tão evidente que a mudança para usá-los será imediata. Isso também se aplica para Micro-serviços, artefato imutável, etc. Voltando a pergunta - Qual a maneira efetiva para implementar DevOps?

Partindo do que existe hoje e evoluí-lo aos poucos, como dizem os praticantes do Kanban, é de maneira evolucionária. A primeira pergunta que talvez deva ser feita para si e para os outros é - “Quais são os gargalos?” Gargalo (Bottleneck), neste contexto é o que limita a eficiência de um sistema, considerando um sistema a interação entre pessoas, processos e softwares. Muitos de nós já lida com gargalos no dia-a-dia mas num contexto relacionado ao produto ou serviço baseado em software, alguns exemplos:
As transações financeiras estão lentas por causa do do banco de dados está sobrecarregado, muitas vezes o serviço ocupa 100% de CPU e Memória RAM. A aplicação está lenta porque ela não foi planejada para essa quantidade de usuários simultâneos. A versão mais nova do framework XYZ resolveu o problema de desempenho que temos na aplicação mas não podemos mudar até o próximo ciclo de desenvolvimento.
A Teoria das Restrições (Theory of Constraint) de Eliyahu Goldratt é um ótima referência para explorar as limitações de um sistema (não só como software, como mencionado anteriormente neste texto) até conseguir remover a restrição ou impedimento. O que irá acontecer é que outra(s) parte(s) do sistema irá ser o gargalo, num ciclo de melhoria contínua explorando os gargalos mais relevantes para o sistema. Este ciclo é chamado de “As cinco etapas de um processo de melhoria contínua”, estes passos estão bem descritos no livro “A Meta” (The Goal):
1 - Identificar o gargalo do sistema
2 - Explorar o gargalo
3 - Subordinar tudo ao gargalo
4 - Elevar os gargalos do sistema
5 - Se, um passo anterior, um gargalo for superado, voltar ao passo 1.
Um sistema (software) de transação bancária processava a média de 1.500 transações por segundo tranquilamente. Este sistema tinha 3 grande integrações com empresas parceiras: Antifraude, Risco de crédito e Notificação da autoridade financeira. Cada transação é validada por cada uma das empresas parceiras. O sucesso da empresa aumentou gradualmente a média de transações por segundo até alcançar 2.000 transações por segundo, e a performance começar a degradar até paralisar as transações bancárias.
Os testes de desempenho indicavam que o sistema tinha capacidade de suportar 5.000 transações por segundo. Então, porque as transações pararam?
Passado alguns dias de investigação descobriu-se que cada sistema parceiro tinha uma limitação do número de transações por cliente:
Antifraude: 3.000 transações por segundo Risco de Crédito: 2.100 transações por segundo Notificação da Autoridade Financeira: 6.000 transaçõs por segundo Considerando a Teoria das Restrições, o gargalo dos sistemas em conjunto é Risco de Crédito, ele é o limitador ou melhor, os outros sistemas não podem ultrapassar o limite de 2.100 transações por segundo. A razão é porque se passarem deste patamar o sistema de Risco de Crédito não irá processar mais e irá sobrecarregará os outros sistemas.
Obviamente, a solução mais fácil seria aumentar a média de transações por segundo o sistema de Risco de Crédito, contudo, isso não sendo viável a curto prazo e sabendo que há picos de transações de 2.500 transações por segundo. Um das alternativas é criar uma fila para enviar as transações ao Risco de Crédito e restringir as transações para não ultrapassar o limite de 2.100 transações por segundo. O excedente, 400 transações por segundo serão represadas até que possam ser processadas.
Há outros ciclos de feedback além da Teoria das Restrições como OODA Loop de John Boyd, PDCA de Walter A. Shewhart, PDSA de W. Edwards Deming são os mais conhecidos. O ciclos de feedback relacionado a DevOps são CAMS (Culture, Automation, Measurement and Sharing) de John Willis e Damon Edwards, ou The Three Way of DevOps de Gene Kim.
Todos têm uma mesma premissa de ciclos curtos e evolutivos, pode escolher qual é o mais adequado mas este é o primeiro passo para implementar. Um ciclo de feedback é fundamental para um processo contínuo de melhoria e aprendizagem. Destes, o que avalio mais importante é o PDSA de Deming.
O que é DevOps, então?
Muitos consideram o encontro do Patrick Debois com Andrew Shaffer em Toronto de 2008 o marco zero. E cronologicamente pode ser considerada como tal, mas o evento mais importante é a apresentação de John Allspaw e Paul Hammond, “10 Deploys por dia” no Flickr, ela influenciou Debois a organizar o DevOpsDays.
Esta apresentação tem praticamente tudo o que consideramos importante para se implementar DevOps atualmente: ChatOps por IRC, Observabilidade usando introspecção e as ferramentas de monitoramento da época (2009), cooperação entre equipes focada em entregar valor e melhorar a resiliência das aplicações, etc.
Se tentarmos ver a essência de todas as palestras, apresentações, textos, vídeos e áudios sobre DevOps desde 2009, há três coisas que sempre estão permeando-as nestes diversos conteúdos:
1 - Pessoas
Por enquanto, até que a supremacia das máquinas e algoritmos prevaleça (Sim, Skynet, estamos esperando você), pessoas são o que fazer as organizações a se moverem. O Jidoka no TPS significa Automação com toque humano, no Manifesto Ágil também, sua primeira linha diz “Indivíduos e interações mais que processos e ferramentas”.
O senso comum sobre DevOps de trabalhar verdadeiramente em conjunto Desenvolvedores e Operações (Infraestrutura), mas na verdade deve ser estendido para todas as outras áreas como segurança, qualidade, etc.
2 - Fluxo
O fluxo também é conhecido como pipeline, o ciclo de desenvolvimento de funcionalidades e correções de bugs até entrar em produção. Ao vermos o fluxo do ponto de vista de uma organização o fluxo é um pouco, envolve todas as áreas: marketing, comercial, suporte ao usuário, tecnologia da informação, etc. Este fluxo maior é conhecido como Fluxo de Valor (Value Stream), tê-lo identificado ajuda a entender como uma organização funciona, a comunicação entre as diversas áreas e onde estão os gargalos.
Fechando o escopo para Tecnologia da Informação, a essência do fluxo é pipeline ou melhor, é Continuous Delivery (Entrega Contínua) com outros Continuous, Deploy e Integration (Integração). A implementação destes tipos de ferramentas no ciclo de desenvolvimento de software podem diminuir significativamente o Lead Time for Commit (desde o momento que um programador desenvolve uma funcionalidade e envia para um repositório de código como Git), implementando testes de qualidade, integração, segurança e outros.
3 - Resiliência
Operações, aqui na Brasil é mais comum de chamar de Infraestrutura, é manter os serviços funcionando. Por muito tempo o senso comum era manter a disponibilidade mais alta possível, era comum os sysadmins estufarem o peito e afirmarem, por exemplo: “*Tenho um servidor com 300 dias de uptime*”. Monitoramento básico de servidores e serviços, mas quase nunca o comportamento das aplicações.
A Tecnologia da Informação tem se aproximado de práticas de outras áreas como aviação, práticas de Engenharia de Resiliência estão sendo adotadas nas empresas onde a TI tem um peso grande na produção de valor. O reflexo disso é mudança da arquitetura de sistemas e processos para um contexto de mais disponibilidade, resiliência e aprendizado: Exemplos disso: Microsserviços, Circuit Breaker, Blameless Postmortem, etc.
Esta perspectiva é não só prever potenciais bugs, é também pessoas, processos e aplicações estarem melhor preparados para enfrentarem situações de falha de um ou mais componentes deste sistema complexo não prevista, não simuladas ou não treinadas.
Qual o papel das ferramentas em DevOps?
Como não há uma definição clara sobre DevOps, muitas consultorias vendem para organizações a implantação de ferramentas como isso fosse DevOps. Não dá para culpá-los porque o termo não tem uma definição clara. Ferramentas são mais fáceis de vender para organizações do que uma nova cultura, como comprar um objeto (sapatos?) que tem início, meio e fim.
Ferramentas são fundamentais para acelerar a melhoria contínua do fluxo e resiliência. Aplicar restrições nelas possibilitam melhorar o fluxo, aumentar a resiliência e envolver as pessoas num ciclo de feedback para aprendizado mais rápido e contínuo.
Um bom exemplo é numa startup que trabalhei um tempo atrás, não havia nenhum processo automatizado, nenhum processo de qualidade e qualquer outra boa prática de Engenharia de Software. Deploy durava dias, bugs críticos levavam semanas para serem corrigidos e os mesmos tipos de incidentes ocorriam com frequência. As consequẽnciass disso eram muitas pessoas da equipe estarem praticamente em burnout.
Algumas restrições adotadas para o Fluxo:
Havia uma ferramenta para revisão automatizada (Code Climate) mas não era usada, o primeiro passo foi habilitá-la para cada Pull Request que era enviado para os repositórios dos projetos no Github. O segundo passo foi definir quais eram os percentuais de code smell para cada PR que estava subindo. No decorrer do tempo este percentual foi mudando com objetivo de melhorar a qualidade de código.
Isso ajudou muito os desenvolvedores a se tornarem melhores, elevando a qualidade das funcionalidades que eles entregavam. Consequentemente, os desenvolvedores evoluíram muito mais rápido do que no período anterior.
- Percentual mínimo de cobertura de testes num commit
A mesma ferramenta verificava cada PR se havia testes de para novas funcionalidades e também tínhamos regras implícitas para cada funcionalidade que houvesse alteração também seria acrescentado teste. O objetivo era ter o mínimo de testes nas funções que avaliamos mais importantes do ponto de vista de negócio e de sistema.
- Tempo máximo de testes e build de um commit
A implementação de testes unitário e de integração diminuíram a quantidade de bugs que iam para produção. Contudo, conforme acrescentamos mais testes o tempo para o PR ser aprovado foi acrescentado e se tornando insustentável. Definimos um tempo máximo de execução para PR, separamos testes específicos para cada fase do ciclo de desenvolvimento e isso manteve um tempo razoável para manter o Lead Time for Commit num patamar que acreditávamos saudável.
- Tempo máximo de deploy em produção
Desejávamos diminuir o tempo máximo de deploy de dias para poucos minutos. Nós implantamos o deploy dos artefatos de forma automatizada usando infraestrutura imutável e containers. Os deploys ocorriam praticamente sem incidentes, permitindo as pessoas não terem que fazerem horas extras para.
- Legibilidade de código poderá ser aprovada num commit
Esta métrica não era um dos critérios para aprovar o merge de uma nova funcionalidade, mas faz uma grande diferença quando implementada. Porque o ato de escrever um código não deve ser considerado como um diário pessoal que só a pessoa autora irá ler, é um registro de como uma pessoa desenvolveu uma funcionalidade ou corrigiu um defeito. Este registro deve ser entendível para qualquer outra pessoa, incluso o próprio autor precise modificar aquele registro num momento futuro.
Algumas restrições adotadas para Resiliência:
Segue algumas sugestões de métricas para adotar de forma evolutiva, identificado se a evolução da resiliência não só dos sistemas, como também das equipes e relação entre os dois numa organização.
- Tempo máximo de resolução de um incidente
O Continuous Delivery nos deu segurança para estabelecer um tempo máximo para resolução do incidente. Anteriormente, a resolução levava dias e algumas vezes, fazendo que os desenvolvedores trabalham dias sem parar tentando corrigir o(s) bug(s). Inicialmente, estabelecemos o limite máximo de uma hora para resolver um incidente em produção, “resolver” neste contexto é não, obrigatoriamente, aplicar uma solução definitiva. Voltávamos para uma versão anterior ou aplicava uma solução de contorno (gambiarra).
- Definir indicadores mínimos para SLA, SLO, SLI e Error Budget
O livro do Google sobre Site Reliability Engineering é muito bom, ele mostra como é aplicar Engenharia de Software para Operações de TI. Uma das grandes contribuições são os indicadores SLA (Service-Level Agreement), SLO (Service-Level Objective) , SLI Service-Level Indicator e Error Budget.
Talvez o mais importante deles é o Error Budget, é um indicador no qual define a tolerância máxima de eventuais falhas. Segundo o livro - “*O principal benefício de um error budget é prover um incentivo comum para equipes de desenvolvimento e SRE encontrar o balanço correto entre inovação e confiabilidade.*”
- Falhas, incidentes e indisponibilidades
Tenho um palpite para explorar num futuro próximo, se você tiver uma ideia melhor ou conseguir ter dados a respeito, entre em contato… Voltando, tenho um palpite de ter um indicador relacionado Quantidade de Falhas, Incidentes e Indisponibilidades. Este palpite, por enquanto é:
Falhas > Incidentes > Indisponibilidades
Métricas “DevOps”
O livro “Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations” de Nicole Forsgren, Jez Humble e Gene Kim é uma reflexão do produção do DevOps State Report realizado em conjunto com a Puppet e posteriormente produzido em conjunto com o Google. O livro descreve como medir a implementação de Lean no desenvolvimento de software e DevOps, estabelecendo 4 métricas para indicar a evolução das equipes e organizações.
1 - Qual a frequência de deploy?
2 - Lead Time for changes
3 - Taxa de falhas nas mudanças
4 - Qual o tempo para restaurar um serviço (MTTR)?
Como medir a “Cultura DevOps”?
Uma pergunta difícil de responder, não há uma resposta direta de como medir uma implentação da “Cultura” DevOps, uma boa alteranativa é medir de forma indireta em qual dos três tipos de cultura organizacional definidos por Ron Westrun no texto “A typology of organisational cultures”. Westrun criou a tipologia inicialmente para comparar o processamento de informações em diferente organizações, atualmente tem sido usada como uma forma de medir indiretamente a implementação da Cultura DevOps e/ou se as organizações são psicologicamente seguras.
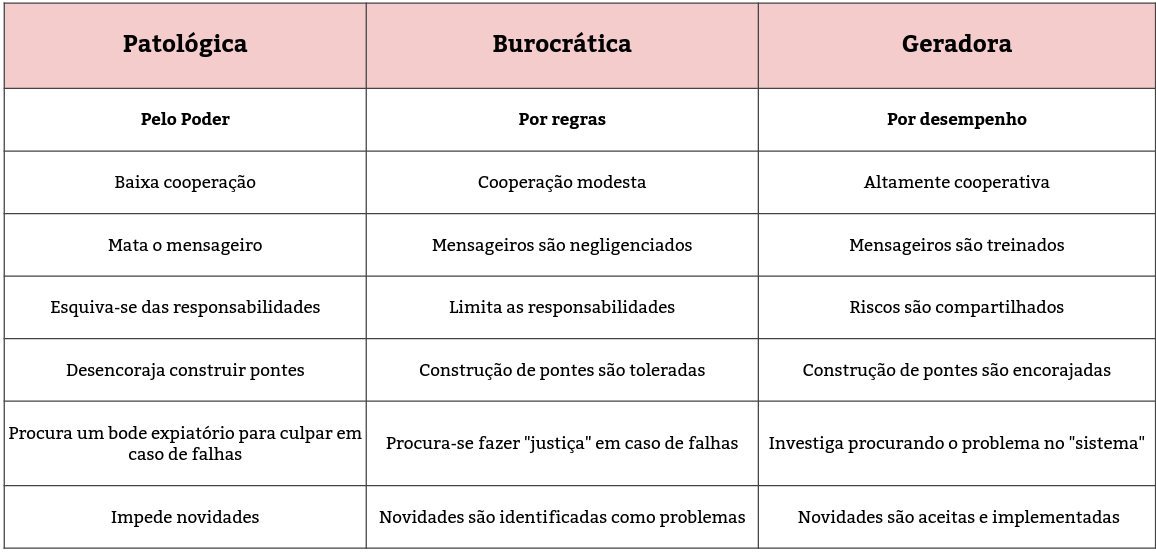
Outros aspectos sobre DevOps
Pensamento científico para leigos, pessoas normais como nós, sempre pareceu ciência de foguete por muito tempo. Isso tem mudado nos últimos anos mas a ciência tem sido refutada com mais veemência como anti vacinas, terra planetas, etc. Ele pode estar muito perto de nós ao considerar a implementação de uma nova arquitetura de sistema, uma nova linguagem de programação, um novo framework, nova metodologia, etc.
Geralmente, as novas ideias tendem ser aceitas quando propostas por pessoas que exercem liderança formal ou informal uma equipe, mas com um pouco de organização de processos pode-se dar voz para ideias de toda equipe levantando qual seria o ganho (hipótese) e comprovando-a através de um experimento controlado, ou como costumamos chamar de prova de conceito.
Um bom exemplo o uso de container, é praticamente certo que ao adotar container, atualmente Kubernetes, há ganhos de produtividade para todas as equipes envolvidas com TI, contudo a implantação dele pode ser bem mais dolorosa se não fizer um processo controlado de experimentação controlado validando o real ganho antes de implementar. Assim, para cada novo serviço, funcionalidade, linguagem, mudanças de arquitetura deve considerar como premissa uma teste controlado com a hipótese a ser considerada, exemplo: Implementando Kubernetes temos um redução de custo de 30% no provedor de IaaS e 40% no Lead Time for Commit. Ao final do experimento poderá comparar com a expectativa inicial, com dados para comparar é mais fácil argumentar a mudança e também dá mais confiança para seguir em frente com a implantação.
Lideranças têm uma grande importância para incentivar experimentação e tomar decisões baseada em dados, elas também são fundamentais para implementar novas metodologias e conceitos que mudam a forma de trabalhar das pessoas numa organização. Elas também podem ser um grande entrave para essas mudanças, então, se a mudança para DevOps está vindo de baixo para cima, considere dizer o que realmente importa, quais benefícios a mudança de uma linguagem ou plataforma teve não importando o termo que a defina.
Lideranças são fundamentais para incentivar um dos aspectos invisíveis mas fundamentais relacionados a DevOps: Aprendizagem Contínua (Continuous Learning). Continuous Delivery não só acelera a entrega de valor mas também acelera o aprendizagem da equipe, como também Engenharia do Caos, Postmortem também aceleram o aprendizado, elevando a qualidade da equipe.
Conclusão
DevOps em 2009 ou quando estiver lendo este texto será um meio para acelerar o Fluxo, Resiliência e Pessoas. Toda a complexidade atual relacionada ao termo está subordinada aos três.
Se a essência, ou melhor, os fundamentos são o mesmo ao decorrer de uma década por que usar Cultura DevOps? Como DevOps é um buzzword, não será estranho em breve surgir ramificações como Business DevOps, Food DevOps ou Battle DevOps. Apenas chame DevOps porque as ferramentas irão mudar, novas técnicas irão surgir mas no fim de um dia de trabalho o que importa é entregar valor sem ficarmos loucos de tanto trabalhar. :)
Se chegou aqui, obrigado pelo seu tempo. Espero que tenho gostado! Se quiser ver os slides, eles estão aqui.